Iris Species Classification using K — Neighbors
Iris is a flower that we could find in gardens. But did you notice that those kinds of flower have various of species even though they look similar? The differences lie on petal or sepal size that we can see at the image below.

There are three species of iris that will be discussed in this articles, consisting of iris setosa, iris versicolor, and iris virginia. Those have distinguish characteristic of either sepal or petal in terms of length and width. Based on data set downloaded from https://www.kaggle.com/uciml/iris, it was plotted between Petal Size and Sepal Size and depicts how Iris Species could be observed.

According to the scatter graphs, at glance, it was easier to classify iris species using petal size, since the specific species data was clustered clearly which is indicated by clustering of purple, blue, and yellow dots. Meanwhile, the Sepal graph shows grouping dots on purple only, not on the yellow and the blue data. As a result, the best assumption how to predict iris classification is to observe petal size rather than sepal size.
K — Neighbors technique is going to use to predict what is the species based on some feature, in this case petal and sepal size. The illustration of this technique is determining of data set by looking at the most species that exist around it.

The data set was divided into two categories, train data (model builder) and test data (model tester) in ratio 7:3 in random way. There were two kind of model, Petal and Sepal model. Based on observation, petal model accuracy accounted 0.96%, while sepal model accuracy just only in 0.65%. Thus, it is proven that the best model to classify iris model is petal model.
Let’s deep dive the accuracy of petal model by comparing true value and predicted result. The image below depicted the matrix classification comparing the number of true and predicted value. It is clear the Iris — setosa was successfully predicted by k — neighbors model, which all true values was equal to predicted setosa values. Meanwhile, iris-versicolor had 15 true value but only 14 data which could be predicted correctly and so had the iris — virginica. As a result, the accuracy was just only 96% and this is quite high probability in prediction model.

That accuracy score was obtained by once splitting data. However, it would be better if splitting the data set for several times in different part of set. This model was known as k — fold validation. The validation was repeated in 5 test splitting and showed various number of accuracy which eventually showed in 95%. Therefore, this means that the model was appropriate in various of splitting way.
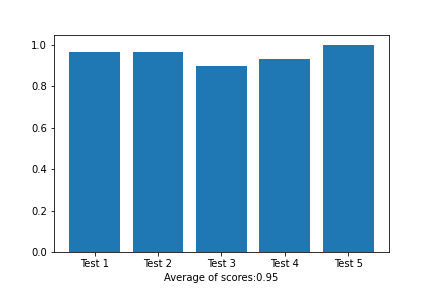
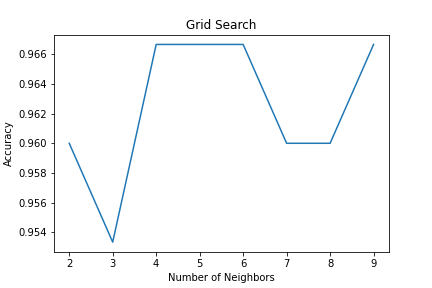
After evaluating splitting technique, it would be better that k — neighbors technique is evaluated as well, since we did not now how many neighbors that should be consider to predict data sample. By the same method, several number of neighbors was evaluated ranging from 2 to 9 dots. As the line chart, it illustrates that 4 neighbors would give higher accuracy which lead to choose this values in order to diminish computation process but still get high accuracy.
In conclusion, k — neighbors model was successfully creating prediction model with 95% accuracy. Do not forget to see how the calculation was done by visiting my github (github.com/azuka31). Cheers